Some days ago, I learned about the RANSAC algorithm (Random Sample Consensus). This is a method to estimate the parameters of a line when the measurements are disturbed by random outliers.
Here is a simple example of a curve fitted (using linear regression) through a set of points, one of which is an outlier:
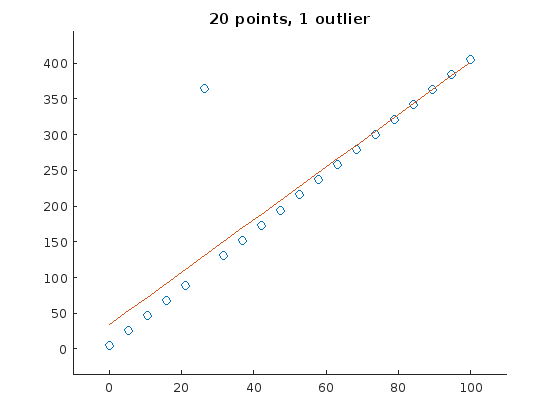
As depicted, one single outlier changes the parameter estimation considerably. RANSACs approach is now to pick a random subset of the points, estimate a line and calculate the distance between this line and each sample. Those samples with a distance lower than a certain threshold are assigned to a the consensus set. This is repeated multiple times and the consensus set of each iteration is stored. Finally, the consensus set with the most entries is selected and the line parameters are estimated from all members of this set.
Here is my alternative approach:
- Initialize the set \(\mathbf{S}\) with all points
- Fit a line through the points in the set \(\mathbf{S}\)
- Calculate distance between line and each sample in \(\mathbf{S}\)
- Select the \(N\) samples with the highest distance to the line, remove them from \(\mathbf{S}\)
- Repeat step 2-4 until an error criterion (e.g. sum of all squared distances between the line and points in \(\mathbf{S}\) is below a certain threshold) is reached$.
Remarks:
- With many outliers, the condition in step 5 is not guaranteed to be fulfilled.
- The algorithm is faster, if you choose higher values for \(N\), but the line will fit worse under some conditions. It seems a good idea to choose high values for \(N\) in the beginning (if there are many outliers) and \(N=1\) if there are few outliers. Thus, \(N\) should be dependent on the mean squared error between line and samples.
Even under harsh conditions, e.g. an initial set \(\mathbf{S}\) with 80% outliers, the algorithm works quite well (finds the correct parameters in 83% of all cases).
Here are three examples. The original line is depicted in orange (in the very first frame). For visualization purposes, a line is drawn only in every fifth iteration.
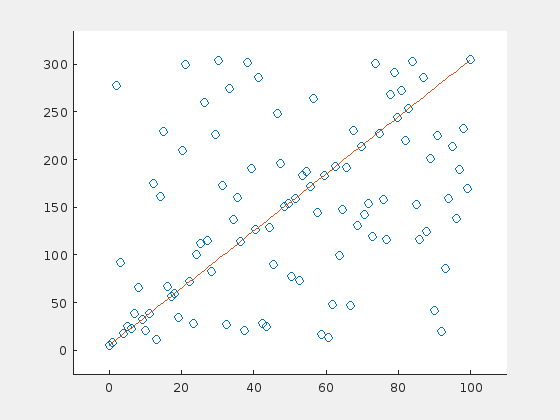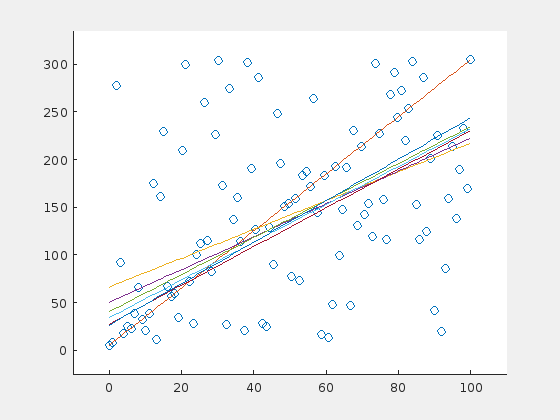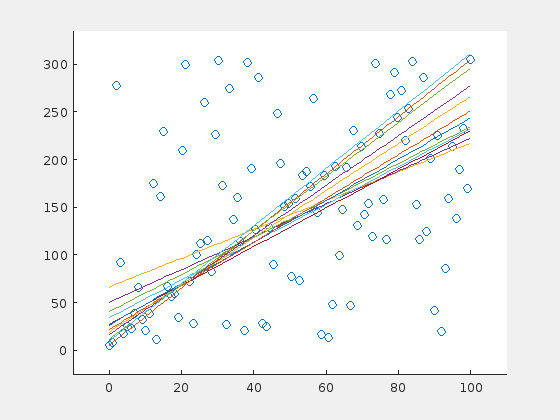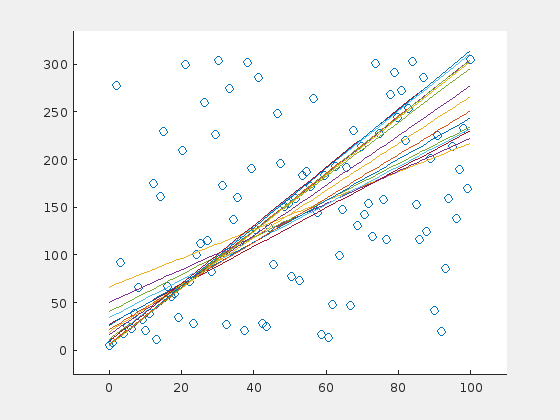
A steep line is detected correctly
A horizontal line is detected correctly
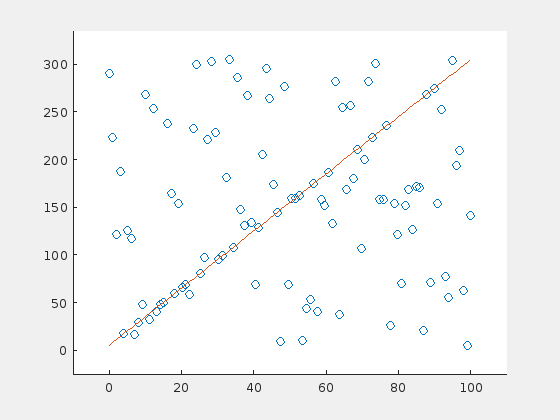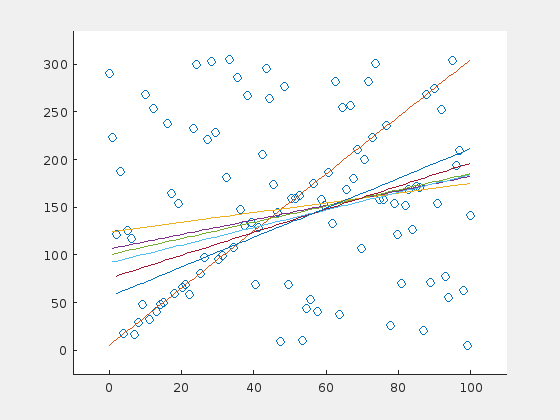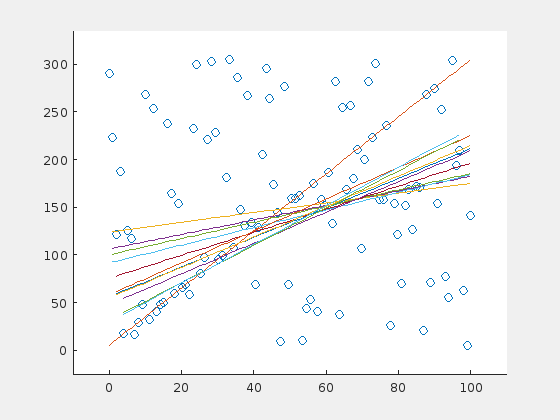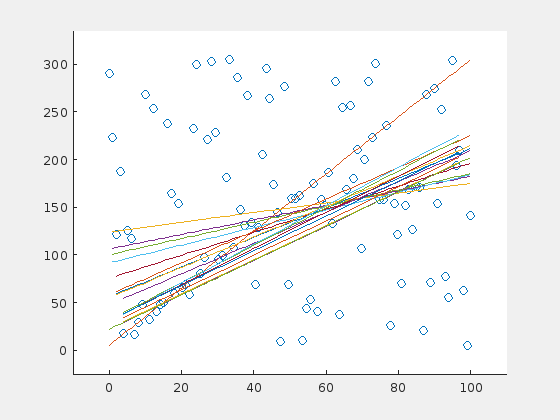
The algorithm fails with this initial set.
Download
You can download the code to generate these gifs here
Part 2: Performance Analysis
With a script, I tested the reliability of the algorithm by varying the number of outliers from 55 to 95 (100 points in total). \(N\) was set to 1 in this case (1 sample deletet per iteration). Below 55 outliers, the algorithm always yielded a good result. above 95, it always failed.
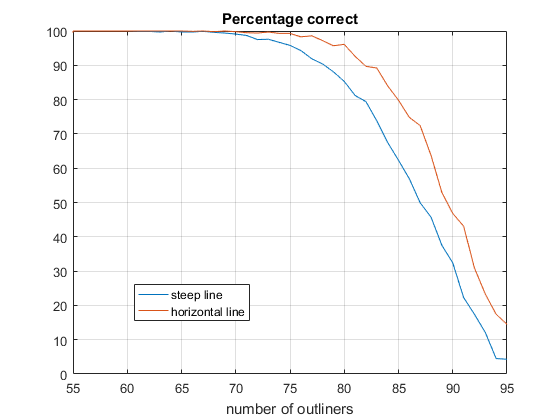
The graphic shows the erorr rate for a steep line and for a horizontal line. At about 75 outliers, the algorithm found the correct line parameters in 90% of the cases. It performs better for the horizontal line.
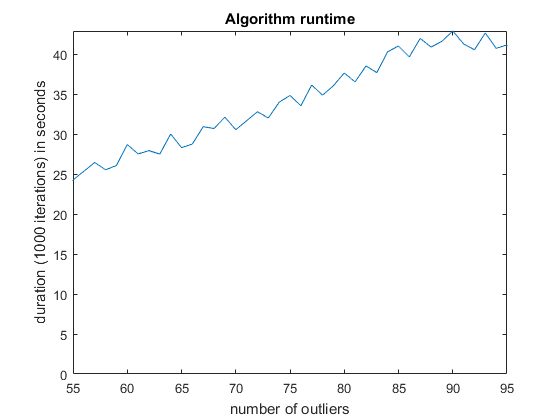
Here is also a runtime plot. The runtime increases linearly with the number of outliers. It oscillates quite strongly, because the test was done in multiple threads to speed it up. But it should give you a rough idea of which performance to expect on a 2013 mid-class cpu (Xeon e3 1225 v3).
Specific cases
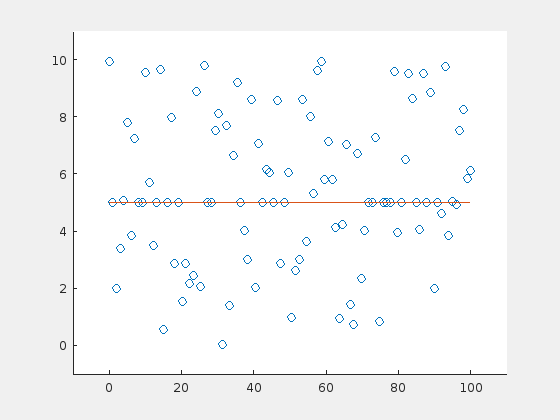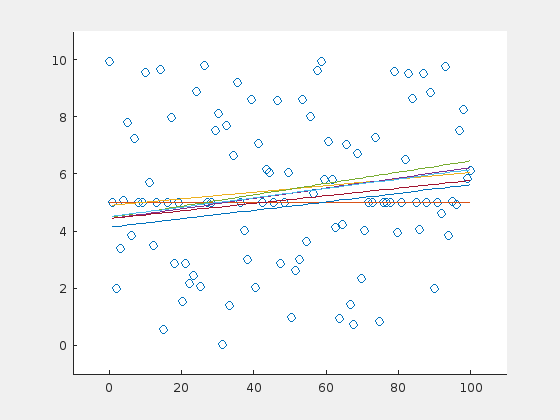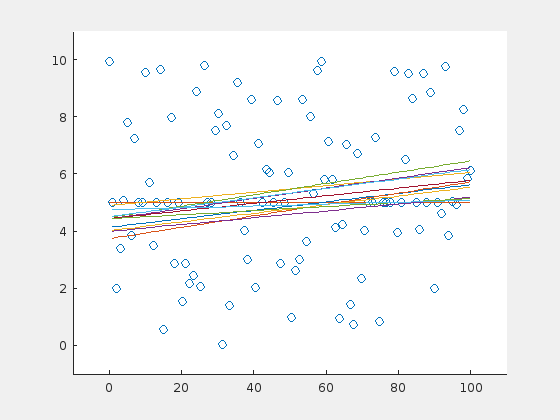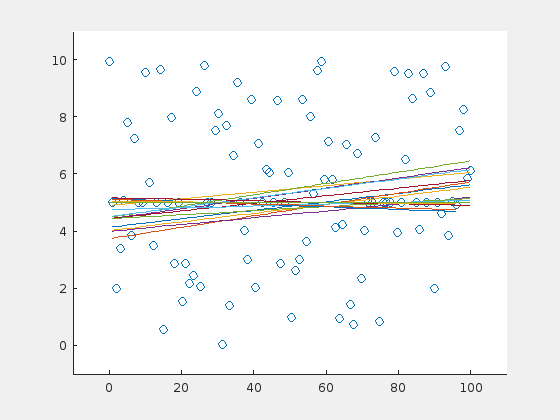
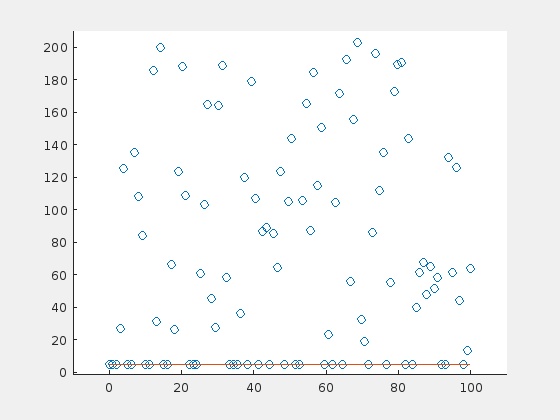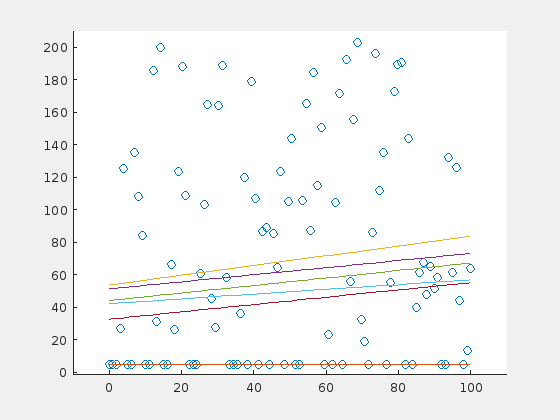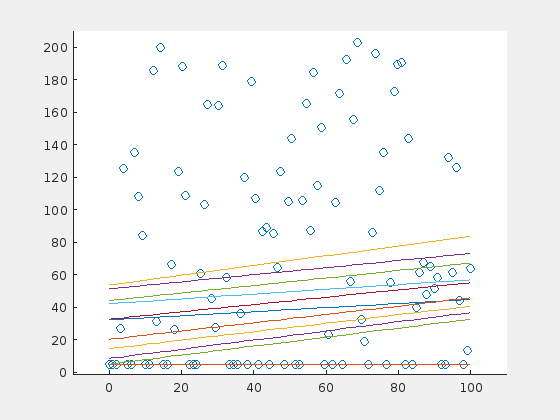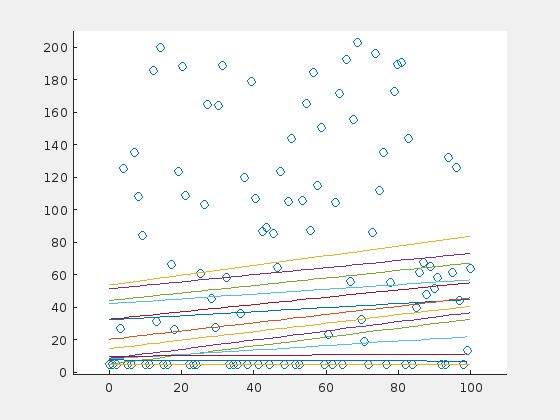
Until now, the outliers were distributed evenly around the line. How do the results change, when the outliers have a preferential side? Here is an example of the extreme case: 70 outliers, all above the horizontal line at \(y=5\):
And here is the same example for a steep line:
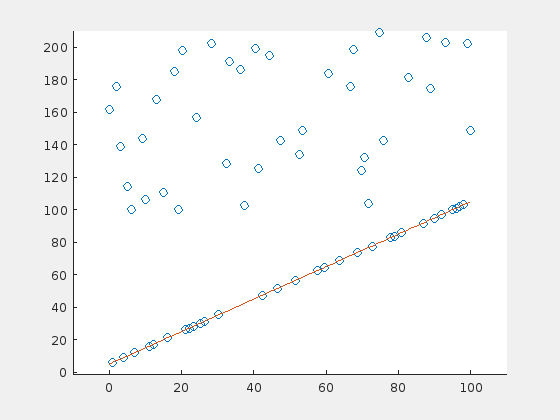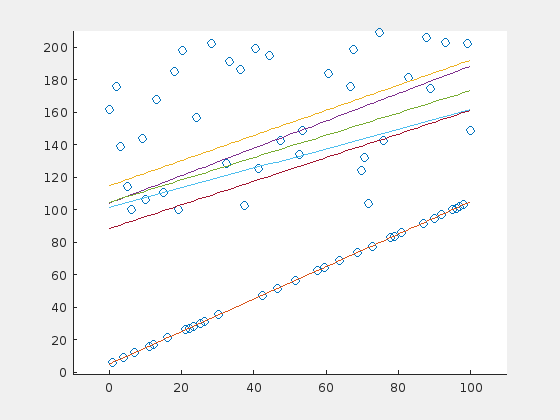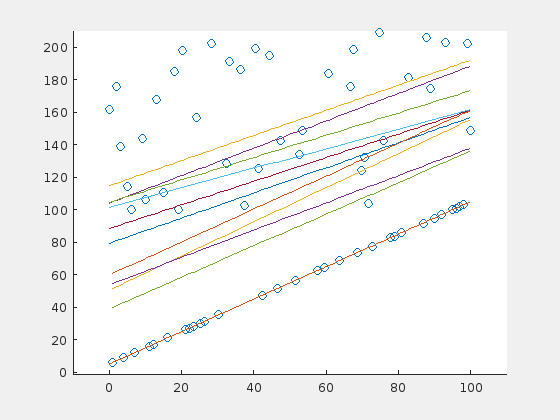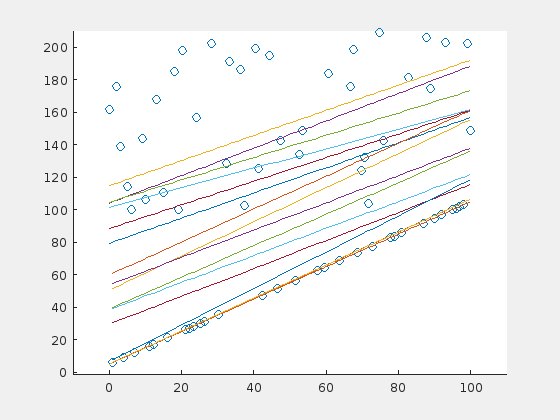
Here is one case in which the RANSAC algorithm probably would perform better. The problem is, that there is a majority of outliers (70%) that are distibuted in a relatively small range above the original line. The outliers “pull” the regression line in their direction, so that the original points are now suspected to be the outliers.
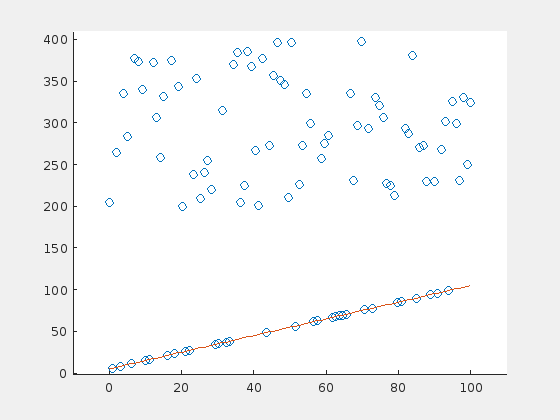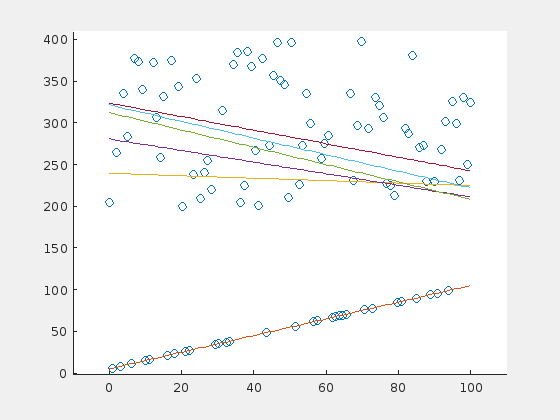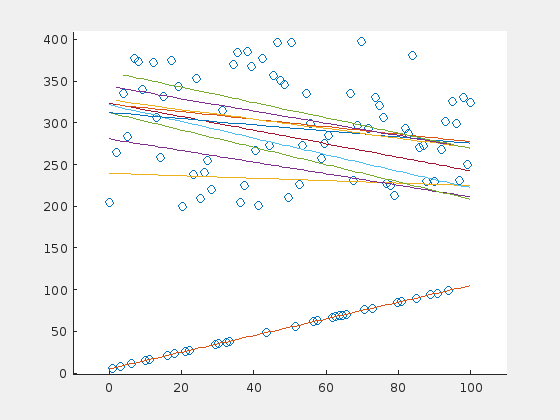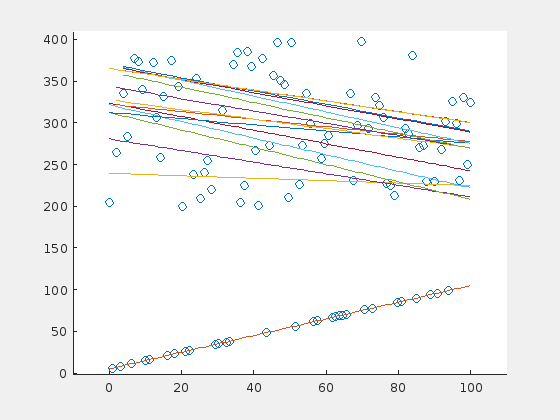
This leads to the assumption that the error rate (percentage of wrong parameter estimations) depends on
- \(\mu_\text{out}\) being the mean offset of the outliers from the original curve,
- \(1 / \sigma_\text{out}\), the variance along the outliers, a smaller variance means a higher error rate,
- \(\sigma_\text{corr}\), the variance along the correct points (in this case, the variance was always chosen to be 0)
- the percentage of outliers.
I will research this in a subsequent post.